SQL Server: FILESTREAM(ファイルストリーム) を使ってファイルを保存する方法
BLOB (Binary Large Object ) と FILESTREAM
SQL Server ベースのアプリケーションでファイルを保存する際には二通りの方法があります。
ひとつは BLOB を通常の varbinary(max) データとしてテーブルに保存する方法、もうひとつは FILESTREAM を使って、 varbinary(max) オブジェクトをファイルシステムに保存する方法です。
どちらを使った方が良いかは、ファイルのサイズや利用方法によって違ってきますが、マイクロソフトによると、保存するファイルのサイズが 1 MB より大きく、高速な読み込みが必要な場合は FILESTREAM の利用が推奨されています。
保存するファイルのサイズが小さいことがわかっている場合は、BLOB としてデータベースに格納するほうがパフォーマンスが良いそうです。
FILESTREAM(ファイルストリーム) を使ってファイルを保存する方法
今回は FILESTREAM(ファイルストリーム) を使ってファイルを保存する方法をご紹介します。
1. FILESTREAM(ファイルストリーム) を有効化する
まず、データベースエンジンの FILESTREAM(ファイルストリーム) を有効化する必要があります。
SQL Server Configuration Manager で有効化したいデータベースエンジンのインスタンスを右クリックし Properties を表示します。
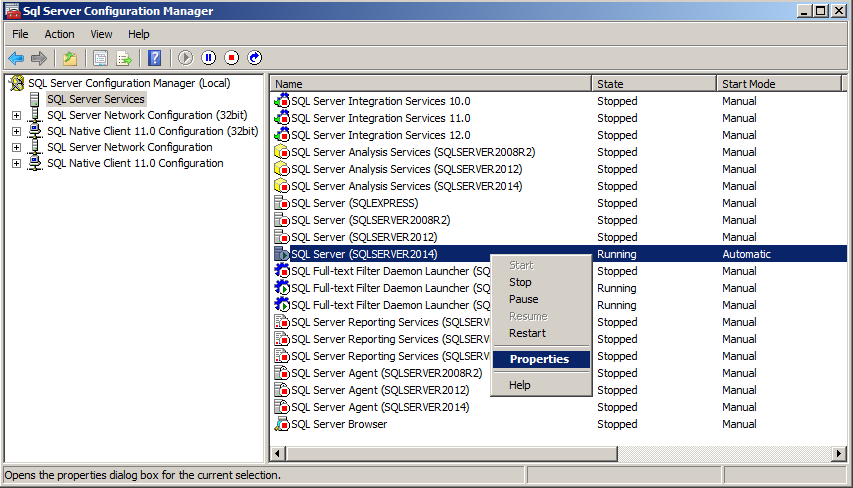
FILESTREAM のタブで、FILESTREAM(ファイルストリーム) を有効化します。 オプションについては以下の通りです。
7. Windows から FILESTREAM データの読み取りと書き込みを行う場合は、[ファイル I/O ストリーム アクセスに対して FILESTREAM を有効にする] をクリックします。 Windows 共有の名前を [Windows 共有名] ボックスに入力します。
8. この共有に格納された FILESTREAM データにリモート クライアントからアクセスする必要がある場合は、[リモート クライアントに FILESTREAM データへのストリーム アクセスを許可する] を選択します。"
MSDN: FILESTREAM の有効化と構成 より抜粋

OK をクリックしたら、もう一度データベースエンジンのインスタンスを右クリックし、リスタートします。
2. FILESTREAM(ファイルストリーム) のアクセスレベルを設定する
次に、FILESTREAM(ファイルストリーム) のアクセスレベルを設定します。
Managment Studio のクエリーエディタを開き以下のクエリーを実行します。
RECONFIGURE;

設定可能なアクセスレベルは以下の通りです。
0: FILESTREAM サポートを無効
1: Transact-SQL アクセスに対して FILESTREAM を有効
2: Transact-SQL アクセスおよび Win32 ストリーム アクセスに対して FILESTREAM を有効
3. 既存のデータベースに対して FILESTREAM(ファイルストリーム) を有効にする
FILESTREAM が有効なデータベースを作る方法の記事はちょこちょこ見かけるので、ここでは既存のデータベースで FILESTREAM(ファイルストリーム) が使えるように設定する方法を説明します。
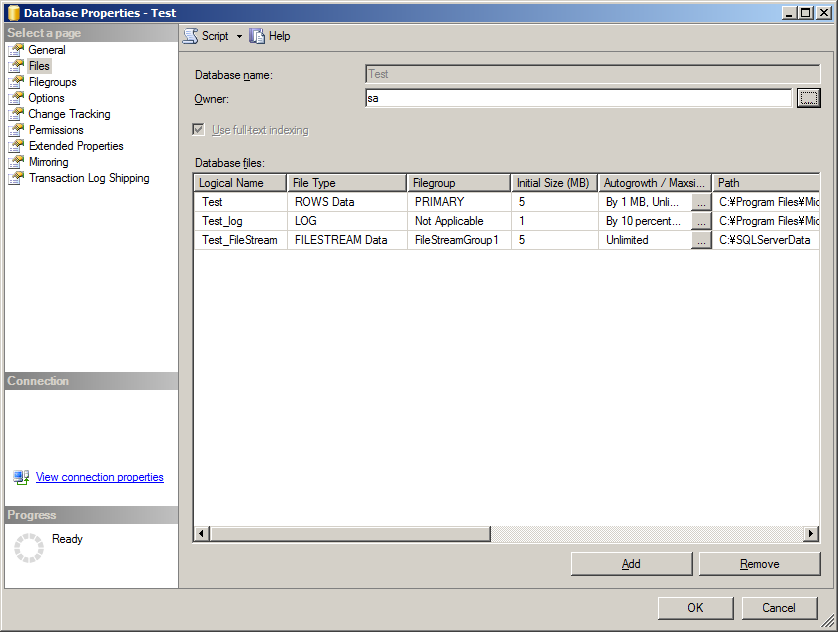
Test データベースで FILESTREAM(ファイルストリーム) を使えるようにしてみましょう。 クエリーでもできますが、今回は GUI から FileStream 用 Filegroups と Files を追加します。
SQL Server Management Studio の Object Explorer で Test データベースを右クリックし、Properties 画面を開きます。
左側で Filegroups のページを選択し、中央の FILESTREAM セクションの Add Filegroup ボタンをクリックします。
Name を入力して、Default チェックを ON にします。

次に Files ページを選択し、 Add ボタンをクリックします。
Logical Name を入力し、File Type で FILESTREAM Data を選択します。 先程作った Filegroup が自動的に Filegroup に設定されるはずです。
Path に File の保存先の Path を設定し OK ボタンをクリックします。
そうすると、指定した Path に 以下のような Logical Name のフォルダーが生成されます。
filestream.hdr ファイルは FILESTREAM コンテナーのヘッダーファイルで、重要なシステムファイルなので、削除変更しないように気をつけましょう。

4. FILESTREAM(ファイルストリーム)データを保存するテーブルを作る
FILESTREAM(ファイルストリーム)データを保存するテーブルを作ってみましょう。
以下のスクリプトを実行して、UploadFile という名前のテーブルを作成します。
FileID UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL PRIMARY KEY,
FileData VARBINARY(MAX) FILESTREAM NULL,
UploadFileName NVARCHAR(100) NULL
);
ポイントとしては、テーブルに UNIQUEIDENTIFIER データタイプで、 ROWGUIDCOL プロパティを設定した ID となるカラムを作り、FILESTREAM (ファイルストリーム)データを保存するカラムは、データタイプは VARBINARY(MAX) にし、FILESTREAM アトリビュートを指定します。
5. FILESTREAM (ファイルストリーム)を使ってファイルを保存する
No. 4 で作ったテーブルにファイルを保存するには、C# などで、ファイルを byte 配列に読み込んだら、そのバイト配列を普通のデータのように Insert するだけで OK です!
@UploadFileName NVARCHAR(100) = 'Text.xlsx';
INSERT INTO UploadFile (
FileID,
FileData,
UploadFileName
)
VALUES (
NEWID(),
@FileData,
@UploadFileName
);


File で設定した保存先の Path を確認すると、その下にディレクトリーが二つくらいできて、ファイルが保存されています。

6. ファイルを削除する
DELETE ステートメントなどを使って、普通にレコードを削除するとファイルも削除されたことになるのですが、ディレクトリに保存されている実際のファイルはただちには削除されません。
データベースのリカバリーモデルや、トランザクションの状態など、いろいろな条件が合った時に Garbage Collector が後で削除します。
私が今回サンプルとして作った Test データベースは、 SQL Server 2014 でリカバリーモデルは FULL、その他も全てデフォルトのままですが、以下のようにトランザクションログをバックアップして、チェックポイントを生成し、ガベージコレクターを手動で実行することによって削除されました。
TO DISK = 'C:\Program Files\Microsoft SQL Server\MSSQL12.SQLSERVER2014\MSSQL\Backup\test.trn'
WITH COMPRESSION;
CHECKPOINT;
EXEC sp_filestream_force_garbage_collection @dbname = N'Test';

